Overview
Transformer最早提出自Attention Is All You Need这篇论文,是一种完全基于Attention的模型结构,在此之前Attention通常和RNN一起使用。
Transformers是后续大模型的骨架,BERT、GPT底层都是Transformer。
Architecture
Attention without RNN
- Attention的输入有两个部分
- Encoder的输入 vectors
- Decoder的输入 vectors
- K(Keys), Values(V): 基于Encoder的输入,通过两个学习到的Weight
、 将 投影到 和 这样每个 就可以得到一个 和一个 - Q(Query): 基于Decoder的输入,也是通过学习到的Weight
将 投影到 这样每个 就可以得到一个
- Encoder的输入 vectors
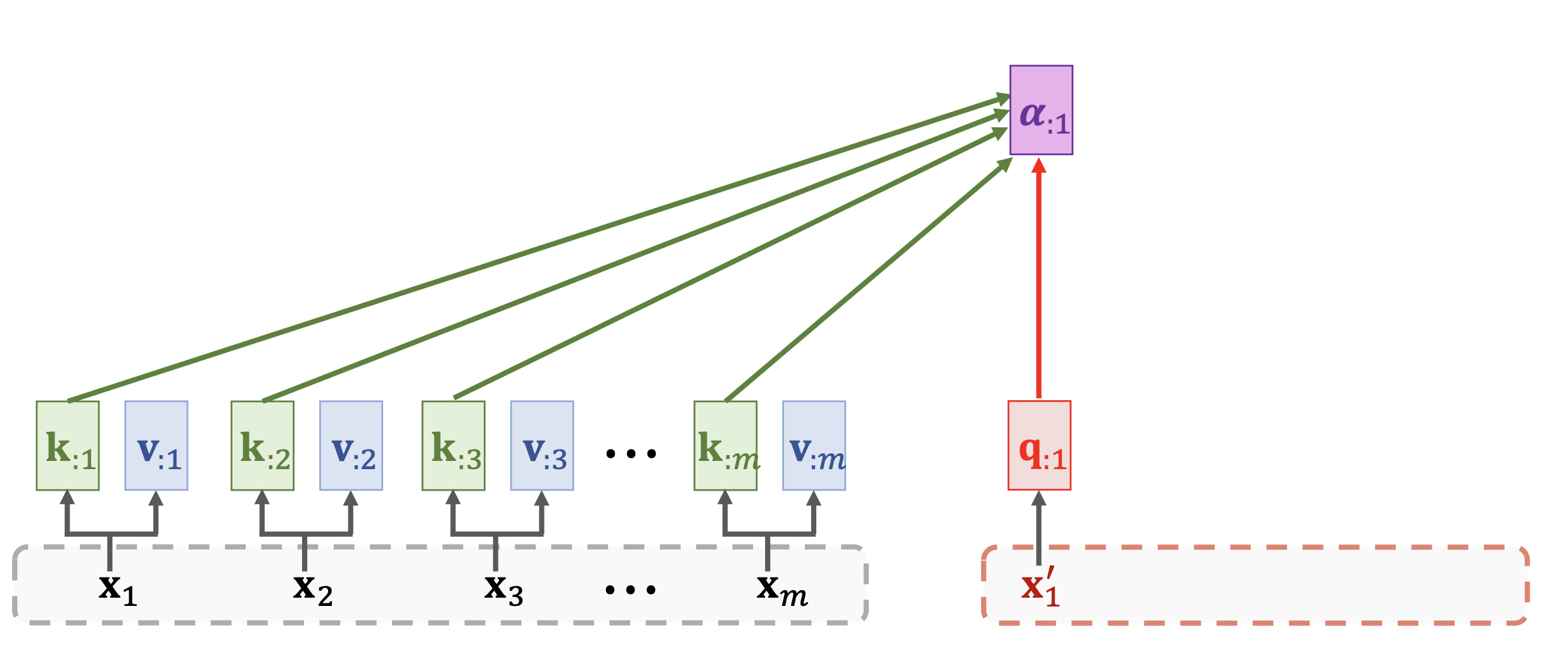
- 之后的计算部分,需要计算一个基于k和q相似度的attention score
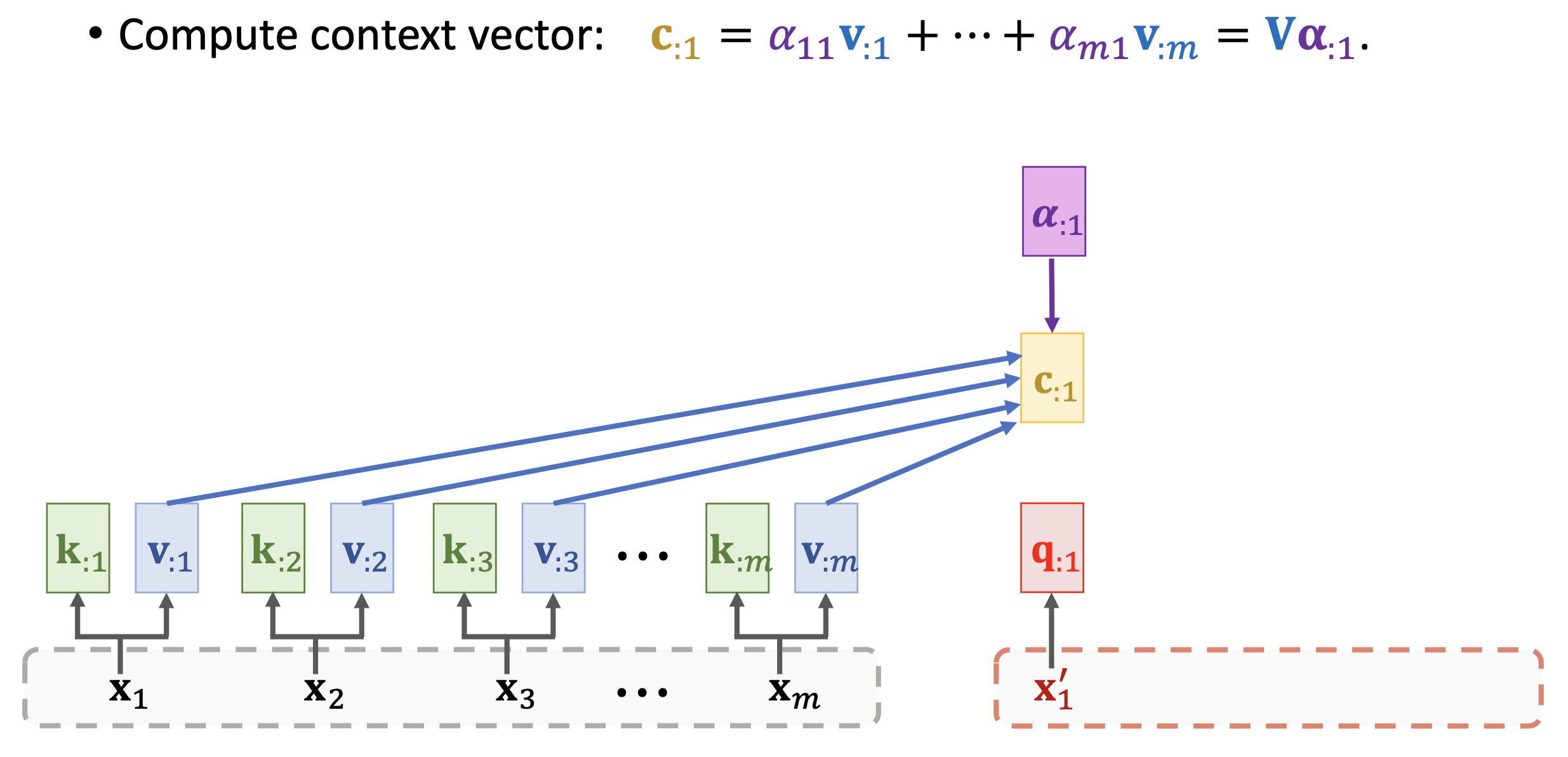
和 基于attention score 和 v的context c。如果作为输出的话,可以再将c通过一个Softmax得到最后的输出token。 - 计算attention score
这里的 就是所有 组成的矩阵,也就是说每个attention score都包含了所有encoder的信息和对应q的信息。 - 计算context vector
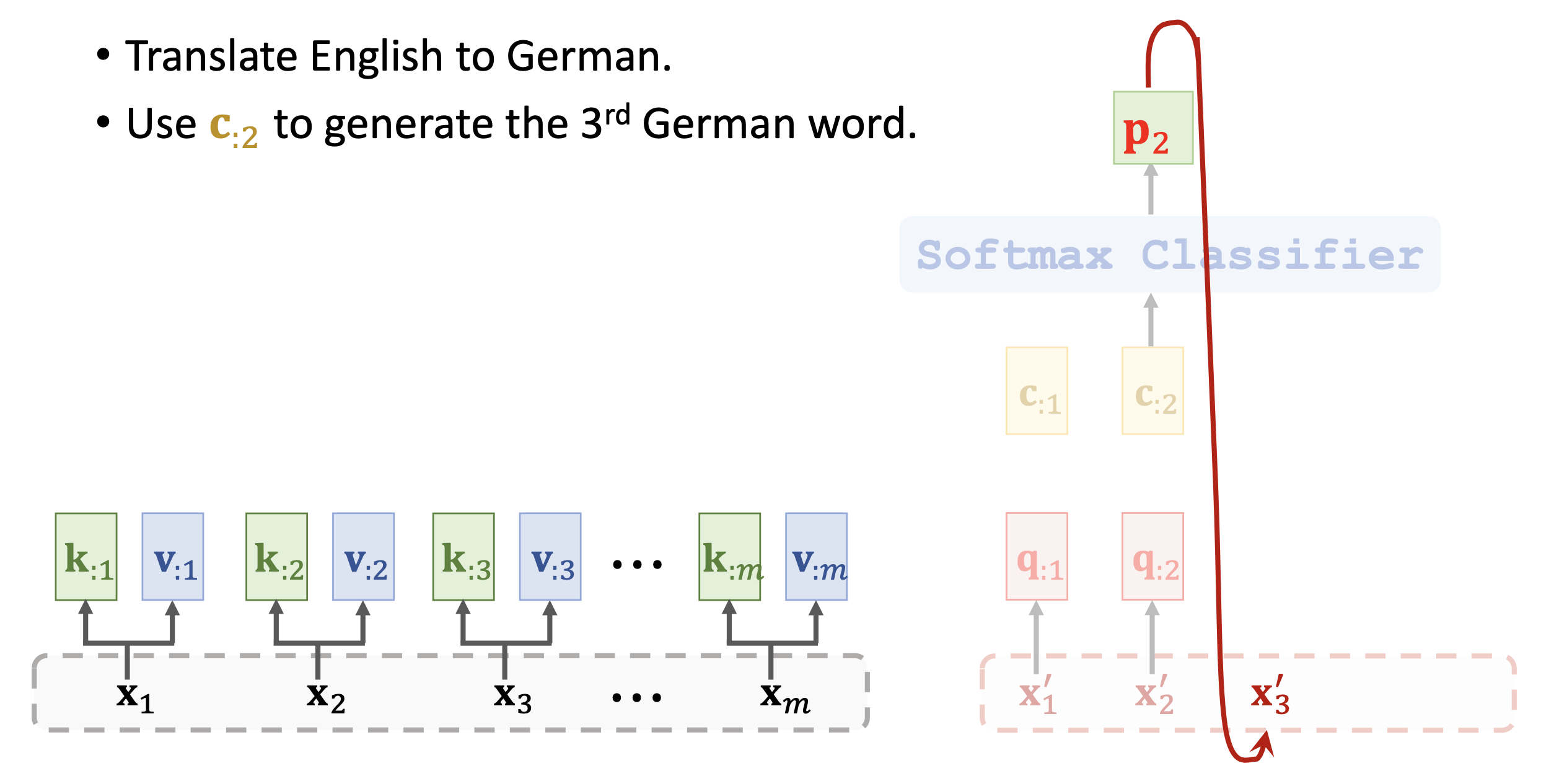
这里的V就是所有 组成的矩阵,也就是说每个context vector包含了所有encoder的信息和对应attention的信息。 - 比如在机器翻译的任务中,我们每次拿一个q和encoder的所有k、v一起生成一个c,然后用c得到输出token,然后再拿新生成的token得到新的decoder的输入
- 计算attention score
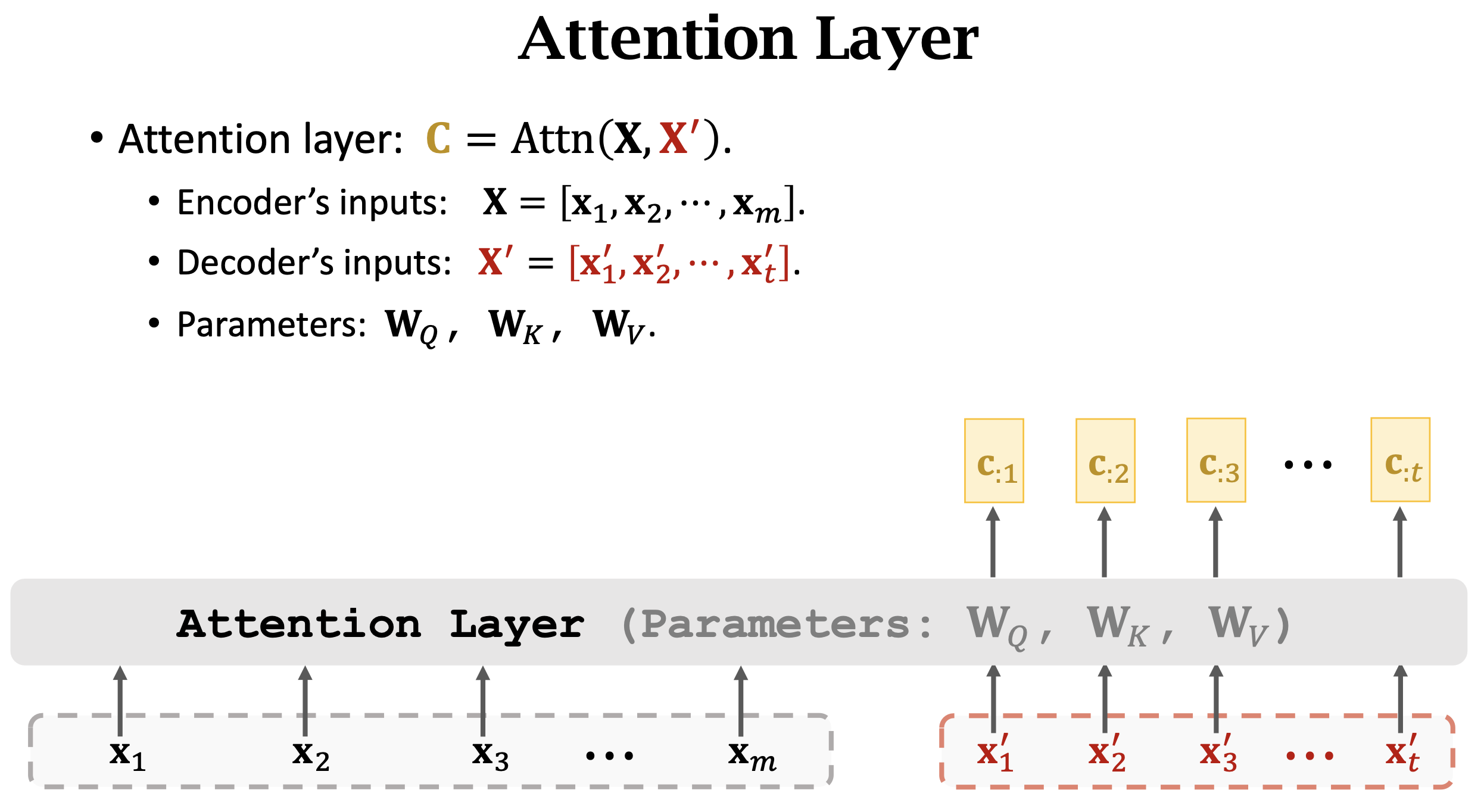
- 合在一起看就是Attention Layer,整个Attention Layer就是通过encoder和decoder的输入
和 ,逐一计算context vector 最后得到整个输出
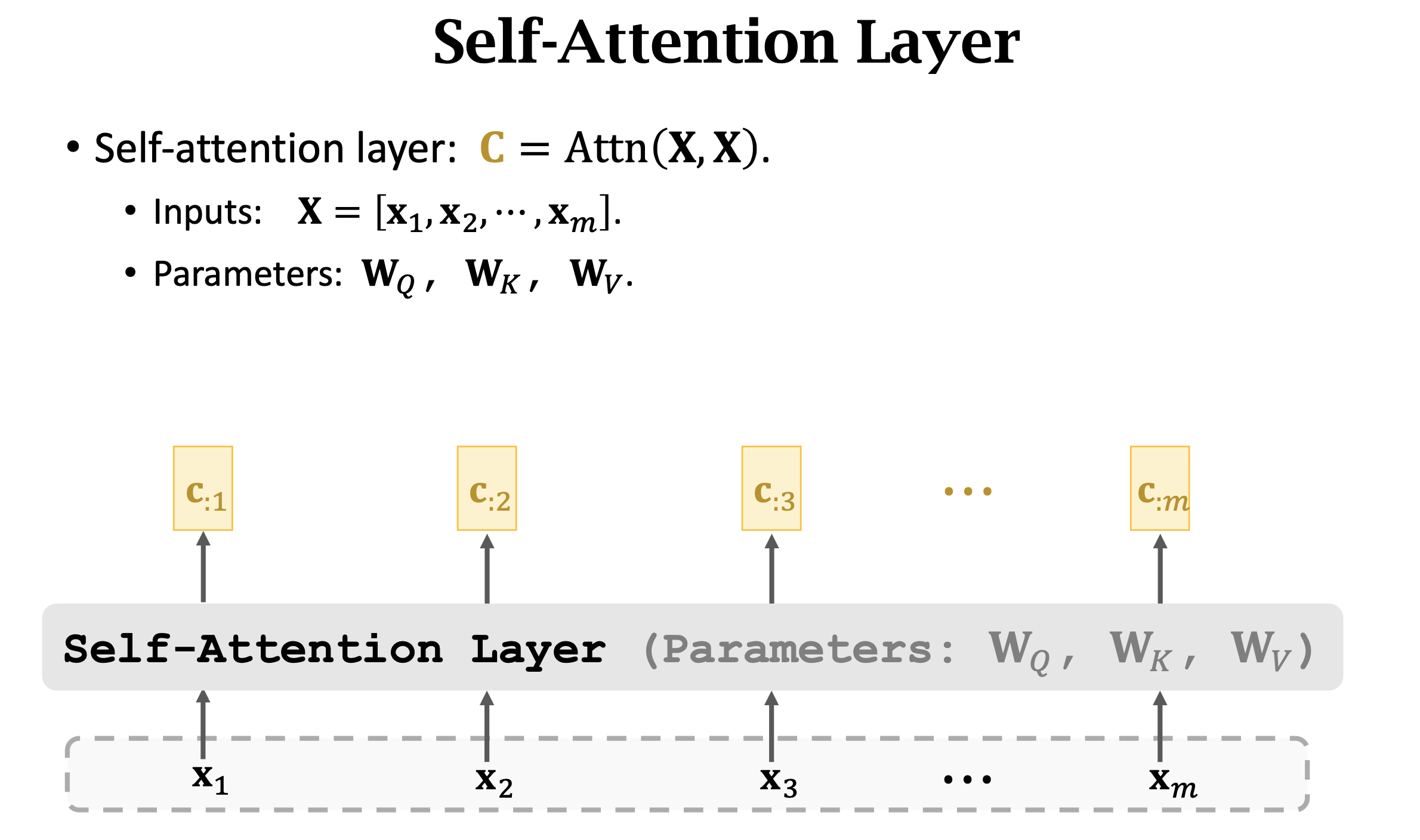
Self-Attention
- Self-Attention是什么呢?
- 其实就是没有decoder输入的Attention。
- 之前q是通过decoder输入得到的,现在q也通过encoder输入来得到,也就是说,每个
我们通过三个Weight 分别得到 - 有了q、k、v之后,后面计算attention和context就和Attention Layer一样了
Multi-Head Attention
- 将
个single-head Attention组合在一起(不share Weight参数) - 然后讲这些single-head Attention的输出做concatenation,比如single-head的输出是一个
的矩阵,那么multi-head的输出就成了 的矩阵 - 这样的Multi-Head Attention就是论文 Attention Is All You Need 中的图了
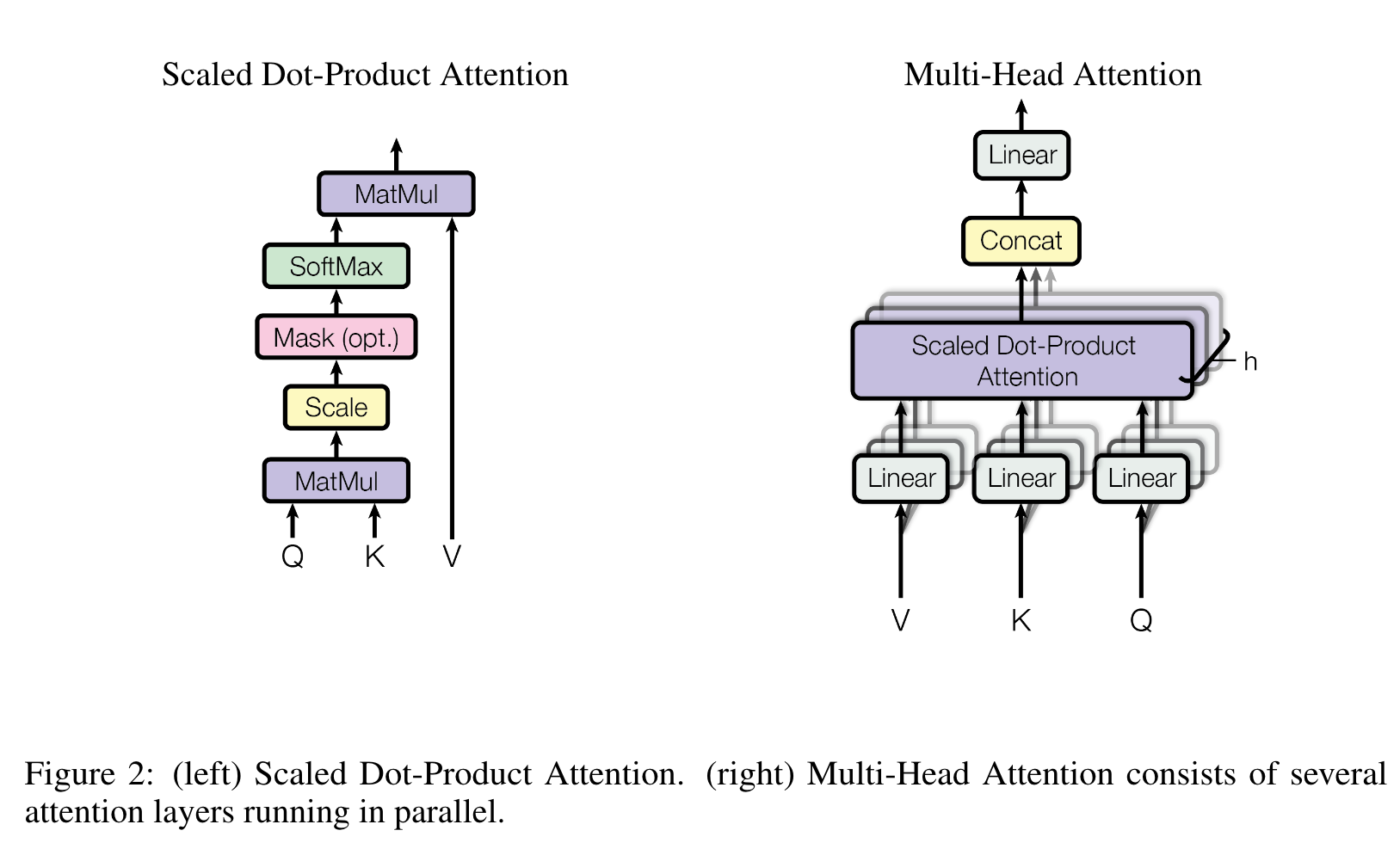
- Scale这里是将Q、K的点积除以
, 指的是Q、K的dimension数量。 - Mask: decoder中计算
i位置的attention score和context的时候不让attendi之前的位置
Transformer Encoder-Decoder Architecture
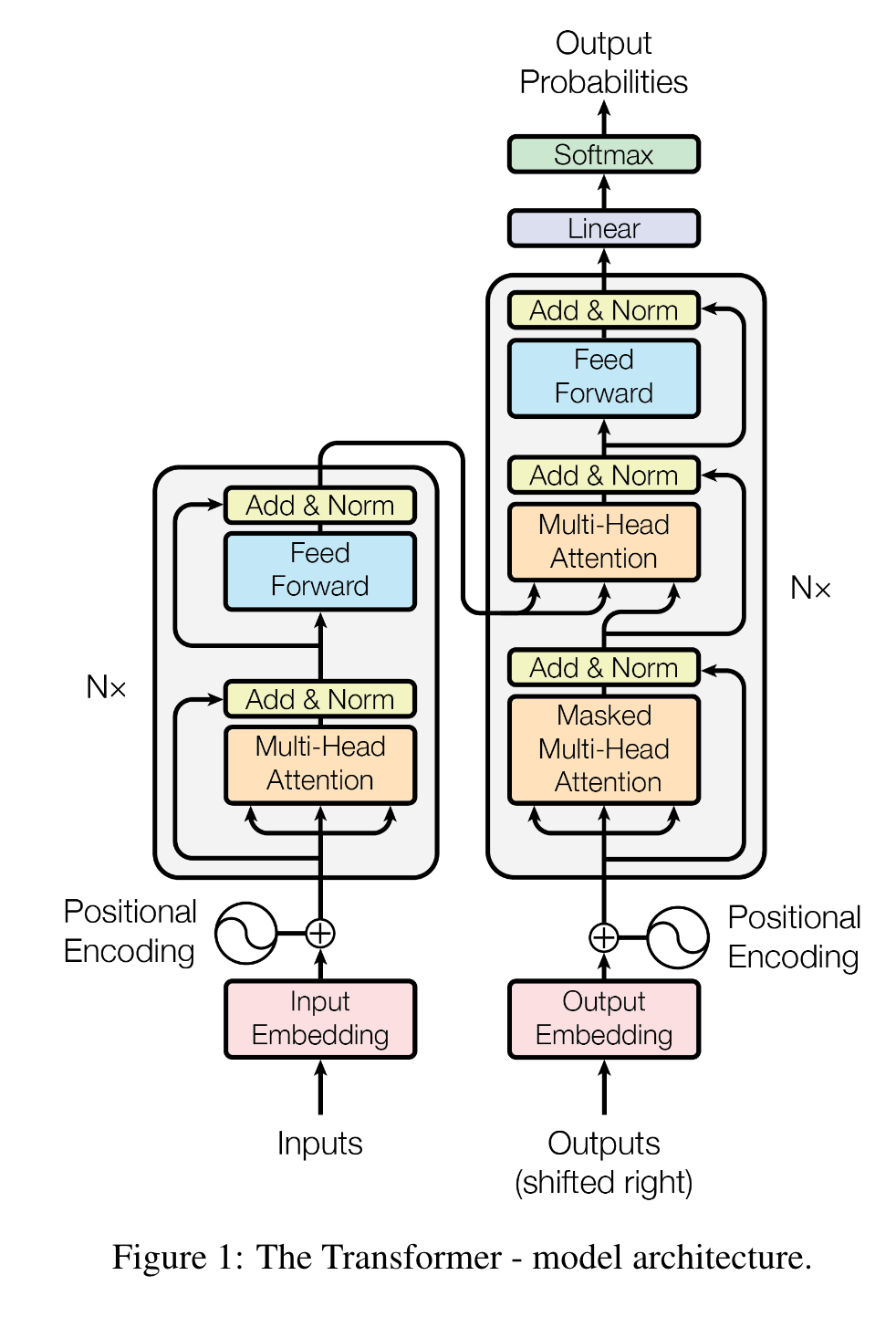
- Encoder Block: 叠加Self-Attention Layers,从图中我们可以看到每个encoder的block由一个Multi-Head Self-Attention和一个Feed Forward(也就是Dense、全连接层),Attention和Feed Forward都接了一个LayerNorm:
subLayer可以是Multi-Head Attention也可以是Feed Forward。 - Decoder Block: 叠加Attention Layers,从图中看到上半部分和encoder相似,一个Multi-Head Attention和一个Feed Forward,不过k、v来自于encoder的输出,而q则来自于下面一个Masked Multi-Head Self-Attention的输出。
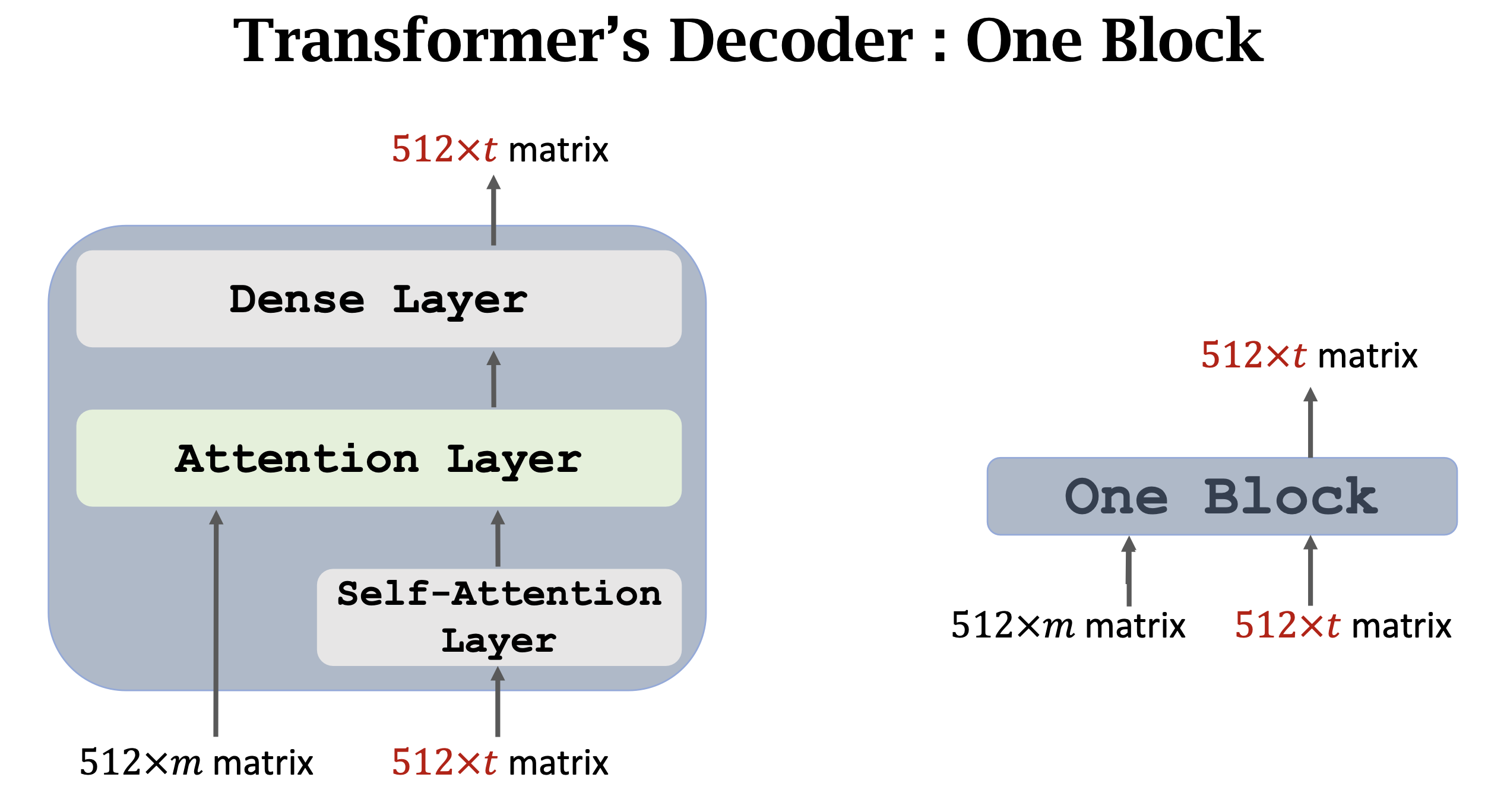
- 整个encoder-decoder的粗略示意图如下:
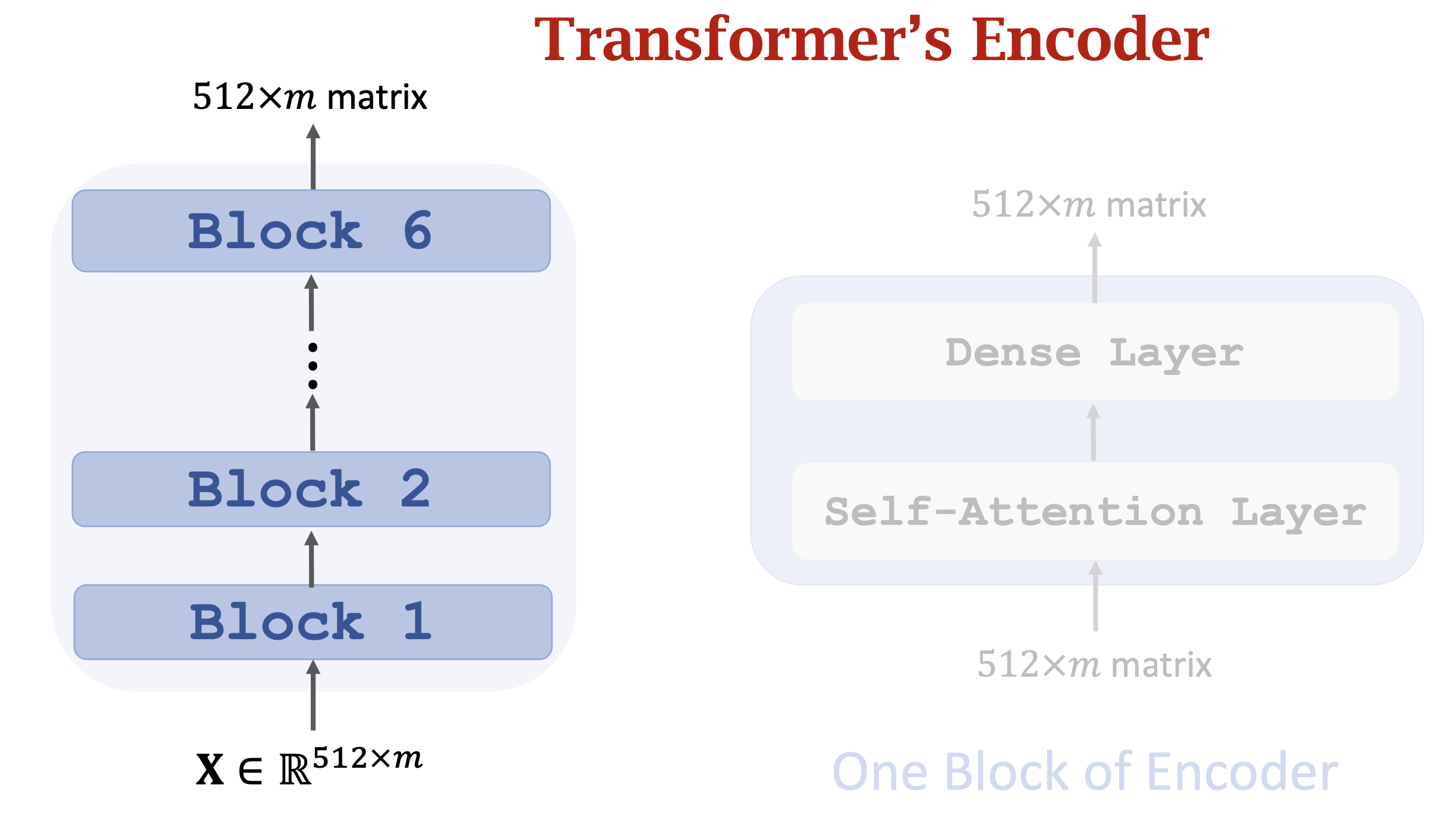
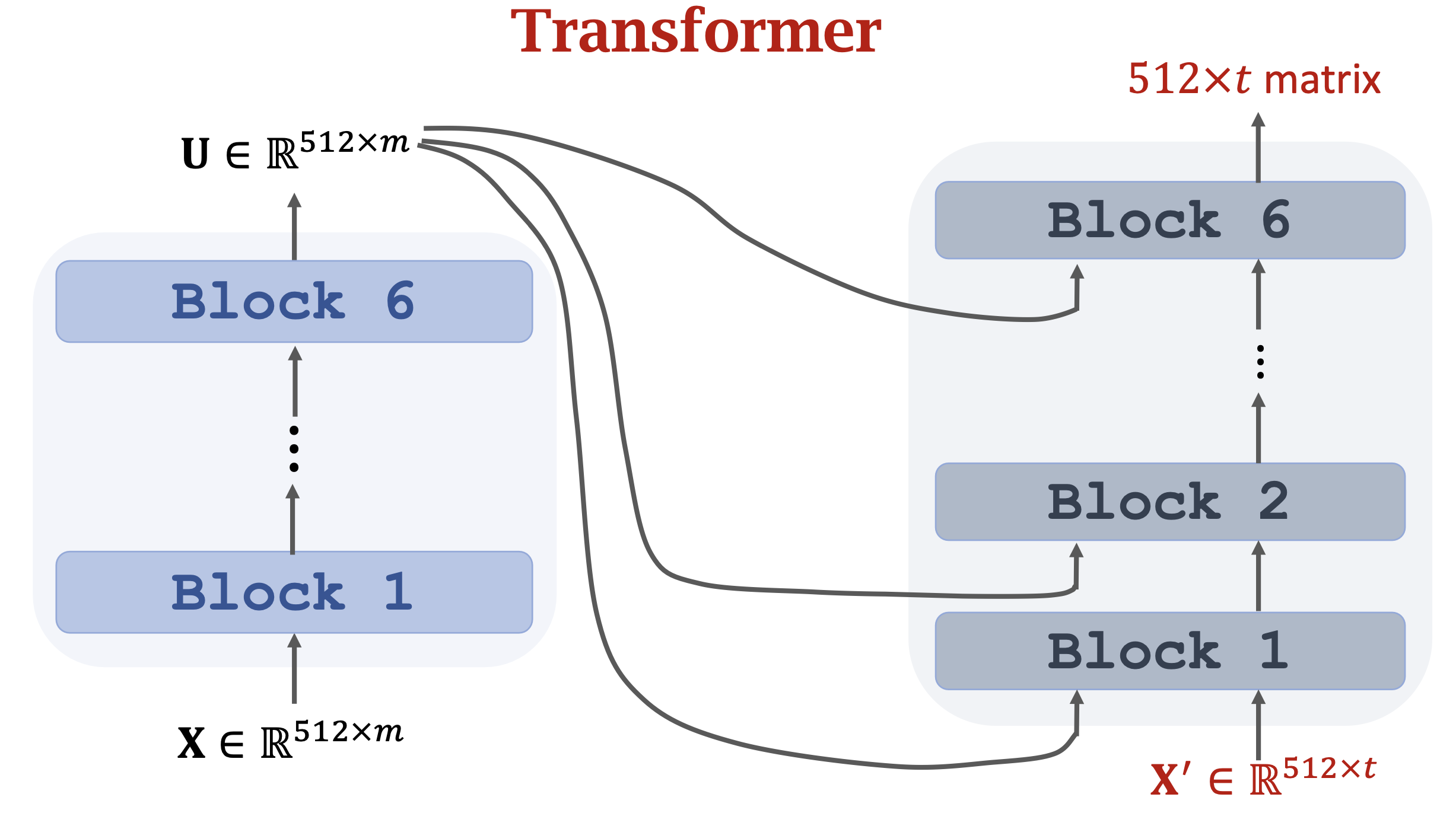
Positional Encoding
- 由于没有了CNN和RNN,我们只是参考了输入每个token的attention权重,但是没有了sequence信息,所以本文加上了position encoding,其方式就是对每个输入token都加上一个相同dimension的embedding
(dim相同,直接做向量加法) - 生成position encoding的方式有很多种,本文使用的是三角函数生成,也可以直接学习一个模型

Example on MT
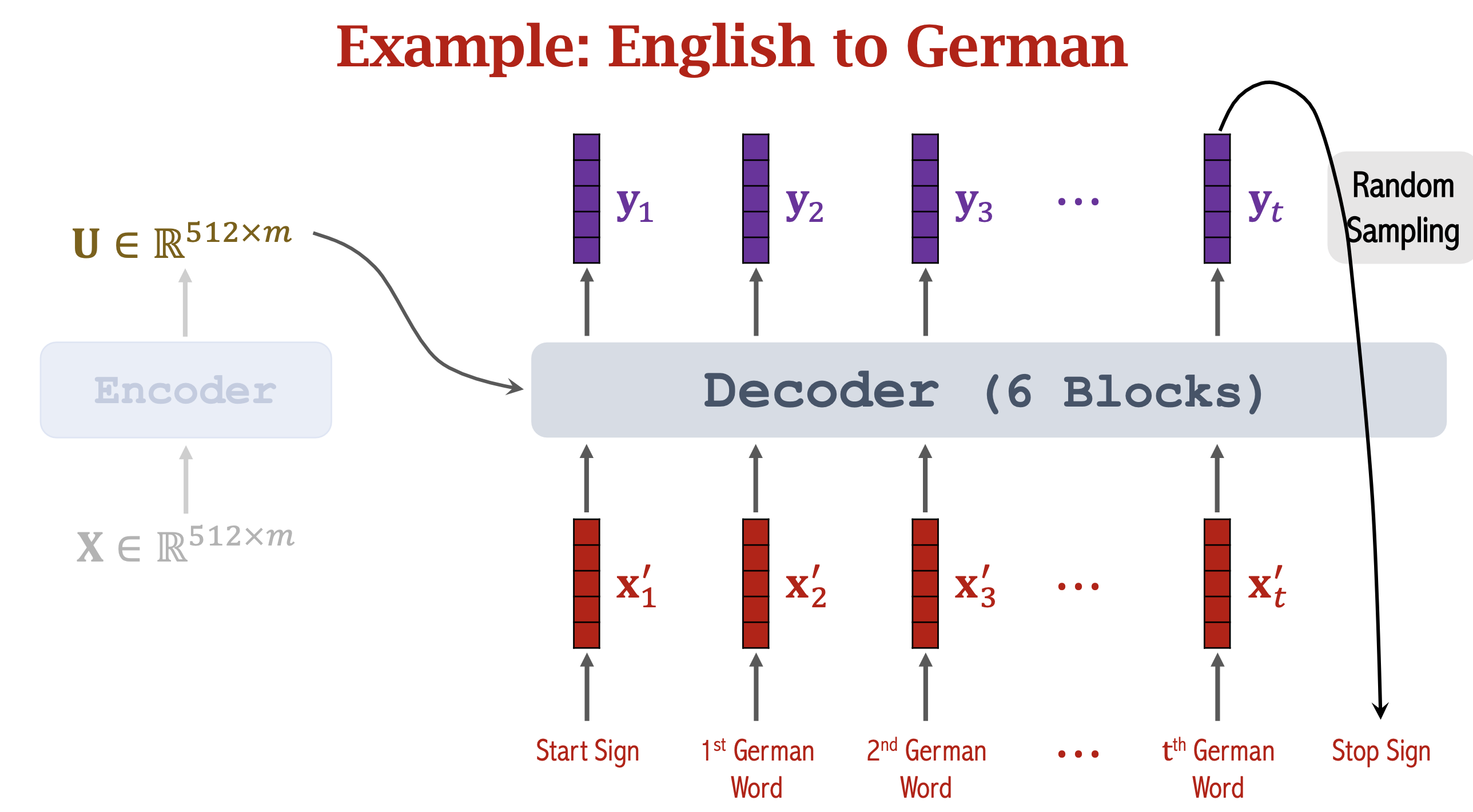
- Encoder部分,输入输出长度对应,m个词输入,编码成m维词向量X,输出依然是相同shape的U,然后decoder从start sign开始,用U和start sign生成y1,y1生成第一个词,然后第一个词输入进decoder得到y2...直到生成出stop sign。